ИССЛЕДОВАНИЕ АРХИТЕКТУРЫ NVIDIA CUDA НА ПРИМЕРЕ РЕШЕНИЯ ЗАДАЧИ УМНОЖЕНИЯ РАЗРЕЖЕННЫХ МАТРИЦ БОЛЬШОЙ РАЗМЕРНОСТИ
Введение
Основным вычислительным компонентом, используемым для высокопроизводительных вычислений, изначально являлся центральный процессор $($CPU$)$. Вместе с тем производители процессоров столкнулись с рядом проблем, связанных с физическими ограничениями при росте частот и высоким энергопотреблением. Сложность возникающих вычислительных задач потребовала резкого увеличения ресурсов и скорости компьютеров. Одним из перспективных направлением повышения скорости решения задач стало осуществление параллельных вычислений. В середине 2000-х для вычислительных целей начали использовать графический процессор $($GPU$)$.
1 Отличия вычислений на CPU и GPU
При сравнении CPU и GPU быстро становится видно их отличие $[1]$, которое заключается в том, что ядра CPU спроектированы для выполнения одного потока последовательных инструкций с максимальной производительностью, а ядра GPU - для быстрого исполнения большого числа параллельно выполняемых потоков инструкций.
CPU представляет собой универсальный процессор или процессор общего назначения, оптимизированный для достижения высокой производительности одного потока команд, обрабатывающего и целые числа, и числа с плавающей точкой. При этом доступ к памяти с данными и инструкциями происходит преимущественно случайным образом. Для повышения производительности современные CPU проектируются так, чтобы выполнять как можно больше инструкций параллельно $[2]$, но это все равно не позволяет осуществлять параллельное выполнение большого числа инструкций, кроме того и накладные расходы на распараллеливание инструкций внутри ядра процессора оказываются существенными. Поэтому процессоры общего назначения имеют не очень большое количество исполнительных блоков.
GPU устроен принципиально иначе, т.к. изначально спроектирован для выполнения огромного количества параллельных потоков команд. Причем данные потоки команд распараллелены изначально, и никаких накладных расходов на распараллеливание инструкций в GPU нет. Отличительными особенностями GPU в сравнении с CPU являются то, что:
- их архитектура, максимально нацелена на увеличение скорости расчета текстур и сложных графических объектов;
- благодаря специализированной архитектуре они более эффективны в обработке графической информации, чем центральные процессоры;
- они проектируются для быстрого исполнения большого числа параллельно выполняемых потоков инструкций;
- предельная мощность типичного GPU намного больше, чем у CPU;
- они обладают более простым доступом к памяти, чем CPU;
- им не требуется кэшпамять большого размера;
- в графических адаптерах применяется более быстрая память, в результате чего им доступна в разы большая пропускная способность памяти, что весьма важно для параллельных расчётов, оперирующих с огромными потоками данных.
Резюмируя можно сказать, что в отличие от более универсальных CPU, GPU предназначены для параллельных вычислений с большим количеством арифметических операций.
В настоящее время вычисления на GPU применяются в таких областях как:
- анализ и обработка изображений и сигналов;
- симуляция физических, биологические процессов и явлений;
- вычислительные математика, биология;
- анализ различных типов данных;
- системы компьютерного зрения и искусственного интеллекта;
- нейросети и т.д.
Основными технологиями для осуществления параллельных вычислений на GPU ведущих производителей графических адаптеров являются NVIDIA CUDA $[3]$ и технология AMD, использующая OpenCL $($фреймворк для создания программ, связанных с параллельными вычислениями$)$. Данные технологии несовместимы друг с другом.
2 Особенности архитектуры CUDA
CUDA $($Compute Unified Device Architecture$)$ - это программно-аппаратная архитектура параллельных вычислений, которая позволяет реализовывать на языке программирования C / C++ и др. алгоритмы математических вычислений, существенно увеличивая вычислительную производительность, благодаря использованию графических процессоров компании NVIDIA восьмого поколения и старше $($серии Geforce 8, Geforce 9, Geforce 200, а также Quadro и Tesla$)$. Данная технология дает возможность реализовать математические вычисления, которые обычно выполняют CPU, благодаря наличию программируемых шейдерных блоков, что позволяет разработчикам программного обеспечения использовать потоковые процессоры видеокарт для выполнения неграфических вычислений.
CUDA позволяет реализовать неграфические вычисления на графических процессорах NVIDIA. Предоставляемый комплект для разработки программного обеспечения $($SDK$)$ обеспечивает программистам реализацию алгоритмов, выполнимых на графических процессорах NVIDIA, и вводит ряд дополнительных расширений для языка C, которые необходимы для написания кода для GPU $[4]$:
- cпецификаторы функций, показывающие каким образом, буду выполняться функции;
- cпецификаторы переменных, служащие для указания типа используемой памяти GPU
- cпецификаторы запуска ядра GPU;
- встроенные переменные для идентификации потоков, блоков и др. параметров при исполнении кода в ядре GPU;
- дополнительные типы переменных.
Для успешной трансляции кода на языке С в состав SDK входит собственный компилятор командной строки nvcс.
CUDA является кроссплатформенным программным обеспечением, обеспечивающим работу в таких операционных систем, как Windows, macOS и Linux. Ее главным минусом является то, что данная технология поддерживается только видеокартами NVIDIA, хотя последние версии поддерживают промышленный стандарт OpenCL, используемый AMD.
3 Установка CUDA Toolkit
Для установки CUDA Toolkit следует скачать инсталляционный пакет с официального сайта производителя $($рисунок 1$)$.

Рисунок 1 — Выбор типа инсталляционного пакета CUDA Toolkit
При этом следует учитывать, что в процессе установки потребуется наличие предварительно установленной среды разработки Microsoft Visual Studio, т.к. осуществляется интеграция инструментов CUDA c ней. Microsoft Visual Studio так же потребуется для сборки и запусков проектом примеров CUDA Samples $($рисунок 2$)$, расположенных, по адресу C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.3. В дальнейшем некоторые из примеров будут нужны для проверки работоспособности CUDA и использующих ее устройств $($видеокарты$)$.

Рисунок 2 — Примеры CUDA Samples для Microsoft Visual Studio 2017 / 2019
Microsoft Visual Studio устанавливается c официального сайта разработчика. Версию устанавливаемой среды разработки $($см. рисунок 2$)$, необходимой для успешной сборки примеров и работы CUDA, следует заранее уточнить согласно документации NVIDIA. В противном случае, тестовые примеры, проверяющие наличие и работоспособность устройств, не соберутся.
В виду того, что при установке CUDA осуществляется интеграция со средой разработки, в последствии ошибка при выборе, чревата еще и тем, что придется заново повторить процесс установки Microsoft Visual Studio и CUDA Toolkit. В нашем случае, для установки CUDA версии 11.3 требуется Microsoft Visual Studio 2019 $($рисунок 3$)$. Более ранние версии Microsoft Visual Studio можно так же скачать c сайта разработчика.

Рисунок 3 — Скачивание установочного пакета Microsoft Visual Studio 2019 Community
Важным моментом при установке является выбор версии самой CUDA, т.к. он зависит от установленного на устройстве (ноутбук, персональный компьютер) графического адаптера и поддерживаемых CUDA драйверов. Например, для GeForce 920M используется драйвер версии 425.31, что соответствует CUDA версии 10.1 и ниже, в то время, как GeForce GTX 960М поддерживает драйвер версии 466.27 и, на момент написания статьи, обеспечивает работу последней версии CUDA - 11.3. Таблицу с данными о драйверах NVIDIA и соответствующих им версиях CUDA можно найти в документации производителя документации производителя. При необходимости производитель предоставляет возможность скачивания более старых версий CUDA Toolkit$($рисунок 4$)$.

Рисунок 4 — Предыдущие версии CUDA, доступные для скачивания
После скачивания следует запустить инсталляционный пакет $($рисунок 5$)$.
Рисунок 5 — Запуск инсталяционного пакета CUDA
Во время установки рекомендуется выбрать Экспресс установку с установкой в папку по умолчанию $($рисунок 6$)$.

Рисунок 6 — Выбор способа установки CUDA
После установки следует проверить наличие компилятора nvcc, введя в командной строке:
nvcc –V
В случае успешной проверки должно появиться сообщение следующего вида $($рисунок 7$)$.

Рисунок 7 — Проверка версии компилятора nvcc
Перед началом работы с CUDA для проверки правильности установки следует скомпилировать пример deviceQuery из CUDA Samples, чтобы обеспечить правильную настройку Microsoft Visual Studio 2019 Community и NVIDIA CUDA Toolkit $($рисунок 8$)$. Данный пример находится при установке в директорию по умолчанию в папке C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.3\1_Utilities $($примеры можно так же взять из репозитория NVIDIA на Github$)$.

Рисунок 8 — Пример запуска скомпилированного файла deviceQuery.exe
Этот пример также помогает понять, какой объем графического процессора установлен в вашем устройстве. На рисунке 8 - это NVIDIA GeForce GTX 960m с видеопамятью 2 ГБ, который может аппаратно поддерживать шейдерную модель 5.0. В дальнейшем эту информацию можно использовать при компиляции файлов CUDA $($имеющих специальное расширение .cu$)$ с помощью компилятора nvcc. Cкомпилированный файл $($релизная версия$)$ примера находится в нашем случае в папке C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.3\bin\win64\Release.
При наличии ошибок при установке $($например, несоответствии драйвера NVIDIA для графического адаптера и установленной версии CUDA$)$ во время запуска примера из консоли вы увидите сообщение $($рисунок 9$)$:
cudaGetDeviceCount returned 3
-> initialization error
Result = FAIL
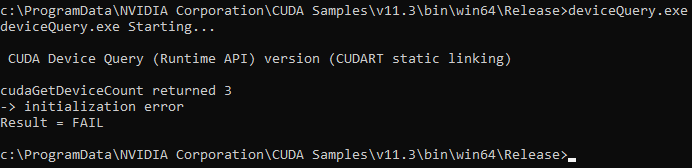
Рисунок 9 — Сообщение, говорящее об ошибках при установке CUDA
При запуске данного примера необходимо убедиться, что устройство было обнаружено, а так же соответствует тому, что установлено в вашей системе, и что тест успешно пройден. Если устройство с поддержкой CUDA и драйвер установлены, но deviceQuery сообщает об отсутствии устройств с поддержкой CUDA, необходимо убедиться, что устройство и драйвер установлены правильно. Одной из часто встречающихся ошибок, является то, что драйвер NVIDIA не соответствует установленной версии CUDA.
Следующим собираемым примером является bandwidthTest, находящийся в том же каталоге, что и deviceQuery. Успешный запуск данного примера гарантирует, что система и устройство с поддержкой CUDA могут правильно обмениваться данными. Результат запуска данного примера должен быть похож на изображенный на рисунке 10.

Рисунок 10 — Пример запуска скомпилированного файла bandwidthTest.exe
Здесь следует обратить внимание на то, что устройство найдено $($на рисунке это GeForce 920M$)$, и подтверждение прохождения всех необходимых тестов. Если тесты не пройдены, следует убедиться, что в вашей системе есть графический процессор NVIDIA с поддержкой CUDA, и убедиться, что он правильно установлен.
Если примеры $($тесты$)$ deviceQuery и bandwidthTest не работают, можно попытаться дополнительно скомпилировать пример deviceQueryDrv $($рисунок 11$)$.

Рисунок 11 — Пример запуска скомпилированного файла deviceQueryDrv.exe
Как правило, данный успешно запущенный пример, показывает, как и deviceQuery наличие CUDA устройств и установленный драйвер CUDA, что при неработающих первых двух примерах часто говорит о несоответствии версии драйвера видеокарты NVIDIA и версии CUDA друг другу. Одним из возможных решений в этом случае является понижение версии устанавливаемого SDK.
4 Вычисления с использованием CUDA
Развитие вычислительной техники позволило перейти к вычислению более сложных моделей $($систем дифференциальных уравнений и их дискретным аналогов$)$, что привело к необходимости решения больших разреженных систем линейных алгебраических уравнений. Как правило решение таких систем связано с операциями с разреженными матрицами большой размерности $($разрежённая матрица - это матрица с преимущественно нулевыми элементами$)$. Выполним на примере умножения разреженных матриц большой размерности сравнение времени выполнения вычислений с использование глобальной и общей памяти на устройстве.
Для этого воспользуемся двумя тестовыми программами, использующими глобальную и общую память на устройстве соответственно. Для создания входных матриц применяется генератор матриц, использующий генератор случайных чисел. В качестве первоначально примера будут использоваться входные матрицы порядка $($16, 16$)$. Результат вычисления при использовании глобальной и общей памяти устройства будет иметь следующий вид $($рисунки 12, 13$)$.

Рисунок 12 — Вычисление с использованием глобальной памяти устройства

Рисунок 13 — Вычисление с использованием общей памяти устройства
Теперь будем постепенно увеличивать размер матрицы для каждой из двух реализаций вычислений и определять время выполнения для каждой реализации. При вычислениях мы будем использовать квадратные матрицы $($число строк равно числу столбцов$)$, размеры которых кратны 16 $($16, 32, 64, 128, 256, …, 4096$)$. Для создания и запуска тестовых программ используем специальные скрипты .cmd, в которые помещаем необходимые входные параметры $($размерности матриц$)$.
Результаты вычислений сведем в таблицы и построим диаграммы зависимости времени выполнения от размера входной матрицы. Диаграммы с таблицами представлены на рисунках 14 и 15.

Рисунок 14 — Диаграмма и таблица результатов вычислений с использованием глобальной памяти устройства
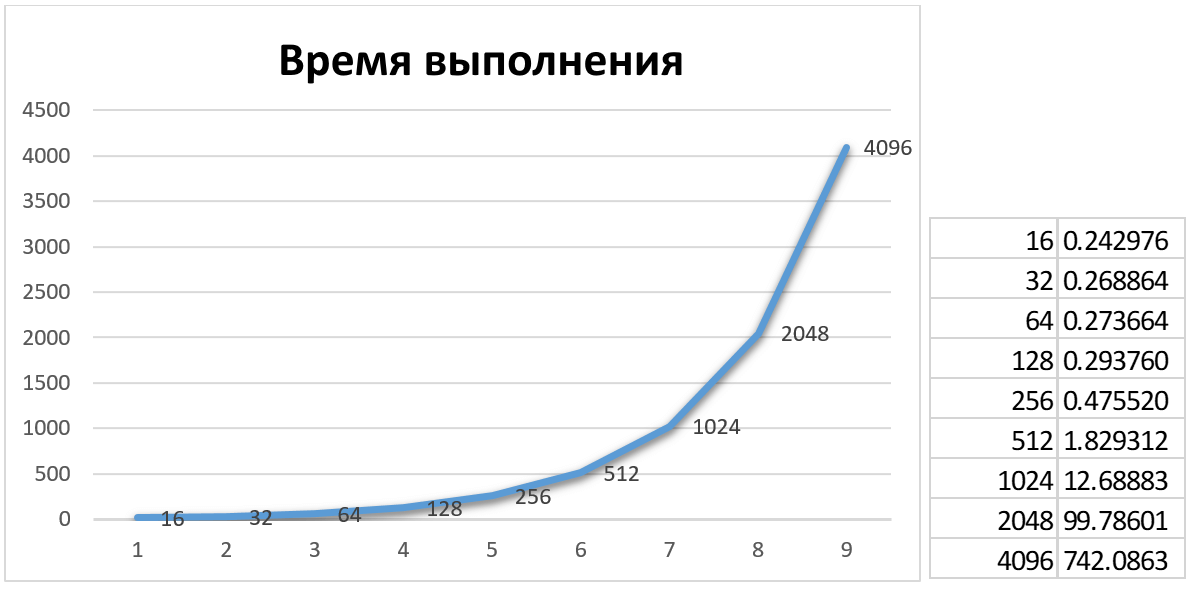
Рисунок 15 — Диаграмма и таблица результатов вычислений с использованием общей памяти устройства
При этом следует отметить, что при увеличении размера матриц, рано или поздно наступает предел вычислительных возможностей, который зависит от параметров устройства. Например, для NVIDIA GeForce GTX 960M ошибка получается при попытке вычислить умножение матриц размером $($8192, 8192$)$ и выше $($рисунок 16$)$.

Рисунок 16 — Ошибка при попытке умножения матрицы размером 8192х8192
Анализ результатов вычислений и диаграмм позволяет выявить разницу в скорости при использовании двух архитектур памяти CUDA. При этом вычисления с использованием общей памяти осуществляются в 2-2,5 раза быстрее, чем при использовании глобальной памяти устройства. Что можно объяснить следующим: все мультипроцессоры графического процессора обращаются к большой глобальной памяти устройства как для операций сбора, так и для операций разброса. Эта память относительно медленная, поскольку не обеспечивает кэширования. Общая память быстрее по сравнению с памятью устройства и ее использование обычно занимает столько же времени, сколько требуется для доступа к регистрам. Общая память является «локальной» для каждого мультипроцессора, в отличие от памяти устройства, и обеспечивает более эффективную локальную синхронизацию. Она разделена на множество частей. Каждый блок потока внутри мультипроцессора обращается к своей собственной части совместно используемой памяти, и эта часть совместно используемой памяти не доступна никаким другим блокам потока того или другого мультипроцессора.
Заключение
Таким образом, на основании примера можно сделать заключение о эффективности использования GPU в задачах с большим количеством однотипных вычислений, что позволяет рекомендовать организовывать вычисления с помощью систем со встроенным графическим процессором. Данные системы позволяют перенести основную вычислительную нагрузку на GPU, способный одновременно производить большое количество параллельных операций, используя его в качестве сопроцессора для CPU.
Список использованных источников
- Пахомов, С. Вычисления на GPU: мифы и реальность $[$Электронный ресурс$]$ / C. Пахомов. - КомпьютерПресс. – 2013.- № 04. - Режим доступа: https://compress.ru. - Дата доступа: 12.05.2021.
- Берило, А. Nvidia CUDA? Неграфические вычисления на графических процессорах $[$Электронный ресурс$]$ / А. Берило. - iXBT.com. - Москва: 2008. - Режим доступа: https://www.ixbt.com. - Дата доступа: 12.05.2021.
- CUDA Toolkit $[$Электронный ресурс$]$ / NVIDIA Corporation. - Santa Clara: 2021. - Режим доступа: https://www.nvidia.com. - Дата доступа: 07.05.2021.
- Max, K. CUDA: Как работает GPU $[$Электронный ресурс$]$ / Max K. - Habr.com. – Москва: 2009. – Режим доступа: https://habr.com. – Дата доступа: 13.05.2021.